Random Algorithm Number & Letter Method
Random Algorithm Number and Letter
-------------------------------------------------------
by: HenSou, Hendra Sousuke a.k.a Hendra Xu
For Letter :
example :
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
Z Y X W V U T S R Q P O N M L K J I H G F E D C B A
the algorithm method is : First - Last Method
so for example :
HENSOU
become
SUMHLF
For Number ( student number) :
we assume there were 26 student in a class
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1
picture line 1.0
so, here are students sit-mates
1 2 3 4 5 6 7 8 9 10 11 12 13
26 25 24 23 22 21 20 19 18 17 16 15 14
picture line 2.0
in number above we see that student with number 1 and number 13 are sit-mates, and so on..
then, next week, or next day, student number 1 and number 13 are sit-mates, look at picture below
1 2 3 4 5 6 7 25 24 23 22 21 20
13 12 11 10 9 8 26 14 15 16 17 18 19
picture line 3.0
so the algorithm method is
number 1 (first) partner with number 26 (last) ,
first partner with last
second first (second) partner with second last..
look at picture line 1.0 or picture line 2.0 above..
from picture 2.0, there are two rows.
we will use First - Last Method again
number 1 partner with number 13, number 2 partner with number 12 and so on..
the result will be like picture 3.0 above
so.. if we goes on... we will find that number 7 would be left alone (no partner) from first row...(Forever alone number 7..hahaha..)
but don't afraid..i would not let my lucky number become forever alone..hahaha...
you will see from picture 3.0 above, that number 7 is partner with number 26..(and then number 7 not forever alone again...hahaha.. Hoorrayy \(^0^)/ LOL.. )
so..number 7 will always partner with first number of second row..
This Algorthim Method originally made by me.
so if there is something wrong, you can comment here..below..
CMIIW...
(Corret Me If I Wrong)
See Ya..!! :)
~Hensou~
Claw-Free Permutation
In mathematical and computer science field of cryptography, a group of three numbers (x,y,z) is said to be a claw of two permutations f0 and f1 if
f0(x) = f1(y) = z
A pair
of permutations f0 and f1 are said to be claw-free if there is no efficient
algorithm for computing a claw.
The terminology claw free was introduced by
Goldwasser, Micali, and Rivest in their 1984 paper, "A Paradoxical
Solution to the Signature Problem",
where they showed that the existence of claw-free
pairs of trapdoor permutations implies the existence of digital
signature schemes secure against adaptive chosen-message attack.
This construction was later superseded by the construction of digital
signatures from any one-way trapdoor permutation.
The existence of trapdoor permutations does not by itself
imply claw-free permutations exist;
however, it has been shown that claw-free permutations do exist if factoring is
hard.
The general notion of claw-free permutation (not necessarily
trapdoor) was further studied by Ivan Damgard
in his PhD thesis The Application of Claw Free Functions in Cryptography
(Aarhus University, 1988), where he showed how to construct Collision Resistant Hash Functions from
claw-free permutations.
The notion of clawfreeness is closely related to that of collision resistance
in hash functions. The distinction is that claw-free permutations are pairs
of functions in which it is hard to create a collision between them, while a
collision-resistant hash function is a single function in which it's hard to
find a collision, i.e. a function H is collision resistant if it's hard
to find a pair of distinct values x,y such that
H(x) = H(y).
In the hash function literature, this is commonly termed a hash collision.
A hash function where collisions are difficult to find is said to have collision resistance.
Constructions
Bit commitment
Given a pair of claw-free permutations f0 and f1 it is straightforward to create a commitment
scheme. To commit to a bit b the sender chooses a random x,
and calculates fb(x). Since both f0 and f1 share the same domain (and range), the bit b is
statistically hidden from the receiver. To open the commitment, the sender
simply sends the randomness x to the receiver. The sender is bound to
his bit because opening a commitment to 1 − b is exactly equivalent
to finding a claw. Notice that like the construction of Collision Resistant
Hash functions, this construction does not require that the claw-free functions
have a trapdoor.
-Hensou-
Encoding permutations as integers via the Lehmer code
This blog post explores the Lehmer code, a way of mapping
integers to permutations. It can be used to compute a random permutation (by
computing a random integer and mapping it to a permutation) and more.
Permutations
A permutation of an array is an array that contains the same
elements, but possibly in a different order. For example, given the array
[ 'a', 'b', 'c' ]
All of its permutations are:
[ 'a', 'b', 'c' ]
[ 'a', 'c', 'b' ]
[ 'b', 'a', 'c' ]
[ 'b', 'c', 'a' ]
[ 'c', 'a', 'b' ]
[ 'c', 'b', 'a' ]
Computing a permutation: a naive solution
In order to motivate the Lehmer code, let’s first implement
a naive algorithm for computing a permutation of an array. Given the following
array arr.
var arr = [ 'a', 'b', 'c' ];
A simple way of computing a random permutation of arr is:
- Compute a random number i, 0 ≤ i < 3. arr[i] is the first element of the permutation. Remove element i from arr.
- Compute a random number i, 0 ≤ i < 2. arr[i] is the second element of the permutation. Remove element i from arr.
- The remaining element of arr is the last element of the permutation.
In order to
implement the above algorithm, we need a function to compute a random integer
in a range starting at 0, up to and excluding an upper bound upper. The following function
performs that duty.
/**
* @returns a number 0 <= n < upper
*/
function getRandomInteger(upper) {
return Math.floor(Math.random() * upper);
}
Furthermore, we don’t want to change the input array arr, which means that we need
a function that non-destructively removes an element:
/**
* @returns a fresh copy of arr, with the element at index removed
*/
function removeElement(arr, index) {
return arr.slice(0, index).concat(arr.slice(index+1));
}
The algorithm itself looks as follows:
function createPermutation(arr) {
if (arr.length === 0) {
return [];
}
var index = getRandomInteger(arr.length);
return [arr[index]].concat(
createPermutation(
removeElement(arr, index)));
}
Interaction:
> createPermutation([ 'a', 'b', 'c' ])
[ 'a', 'c', 'b' ]
Note: createPermutation()
could be implemented more efficiently, but the current implementation expresses
our intentions very clearly.
Encoding permutations as integers
An alternative to the above algorithm is to find a way to
map single integers to permutations. We can then simply compute a random
integer and map it to a permutation.
The naive algorithm in two steps
As a first step towards this new approach, lets first split
up the previous algorithm into two steps:
- Compute the indices for the (continually shrinking) array arr.
- Turn the indices into a permutation.
The
following function performs step 1. We don’t need to know anything about arr, except for its length len. The first index of the
returned array is in the range [0,len), the second in the range [0,len−1), etc.
function createLehmerCode(len) {
var result = [];
for(var i=len; i>0; i--) {
result.push(getRandomInteger(i));
}
return result;
}
Interaction:
> createLehmerCode(3)
[ 0, 1, 0 ]
The above way of encoding a permutation as a sequence of
numbers is called a Lehmer
code. Such a code can easily be converted into a permutation, via the
following function (step 2):
function codeToPermutation(elements, code) {
return code.map(function (index) {
var elem = elements[index];
elements = removeElement(elements, index);
return elem;
});
}
Interaction:
> codeToPermutation(['a','b','c'], [0,0,0])
[ 'a', 'b', 'c' ]
> codeToPermutation(['a','b','c'], [2,1,0])
[ 'c', 'b', 'a' ]
Mapping integers to Lehmer codes
The next step is to replace createLehmerCode() by a function that maps an
integer to a Lehmer code. Afterwards, we compute that integer randomly and not
the code itself, any more. To that end, lets look at ways of encoding sequences
of digits (e.g. indices) as single integers. If each of the digits has the same
range, we can use a positional
system whose radix is the (excluded) upper bound of the range.
The decimal
system. For example, if each digit is in the range 0–9 then
we can use the fixed radix 10 and the decimal system. That is, each digit has
the same radix. “Radix” is just another way of saying “upper bound of a digit”.
The following table reminds us of the decimal system.
Digit position
|
2
|
1
|
0
|
Digit range
|
0–9
|
0–9
|
0–9
|
Multiplier
|
100 = 102
|
10 = 101
|
1 = 100
|
Radix
|
10
|
10
|
10
|
Note that each multiplier is one plus the sum of all previous highest digits multiplied by their multipliers. For example:
100 = 1 + (9x10 + 9x1)
The factoradic
system. Encoding the digits of a Lehmer code into an integer
is more complex, because each digit has a different radix. We want the mapping
to be bijective (a one-to-one mapping without “holes”). The factoradic system
is what we need, as explained via the following table. The digit ranges reflect
the rules of the Lehmer code.
Digit position
|
3
|
2
|
1
|
0
|
Digit range
|
0–3
|
0–2
|
0–1
|
0
|
Multiplier
|
6 = 3!
|
2 = 2!
|
1 = 1!
|
1 = 0!
|
Radix
|
4
|
3
|
2
|
1
|
6 = 1 + (2x2 + 1x1 + 0x1)
The following function performs the mapping from integers to
Lehmer codes.
function integerToCode(int, permSize) {
if (permSize <= 1) {
return [0];
}
var multiplier = factorial(permSize-1);
var digit = Math.floor(int / multiplier);
return [digit].concat(
integerToCode(
int % multiplier,
permSize-1));
}
We start with the highest position. Its digit can be
determined by dividing int
by the position’s multiplier. Afterwards the remainder of that division becomes
the new int and we
continue with the next position.
integerToCode() uses the
following function to compute the factorial of a number: function factorial(n) {
if (n <= 0) {
return 1;
} else {
return n * factorial(n-1);
}
}
Putting everything together
We now have all the pieces to compute a permutation as
originally planned:
function createPermutation(arr) {
var int = getRandomInteger(factorial(arr.length));
var code = integerToCode(int);
return codeToPermutation(arr, code);
}
The range of the random integer representing a permutation
is [0,arr.length).
That is an indication that the mapping between integers and permutations is
really bijective, because arr
has arr.length!
permutations,
Practically useful?
Is the Lehmer code practically useful? It is if you need to
encode permutations as integers. There are two additional use cases for it:
Computing a random permutation and enumerating all permutations. For both use
cases, Lehmer codes give you convenient solutions, but not efficient ones. If
you want efficiency, consider the following two algorithms:
- Computing a random permutation: the Fisher–Yates shuffle
- Enumerating all permutations: the Steinhaus–Johnson–Trotter algorithm
Model Of Conventional Encryption Process
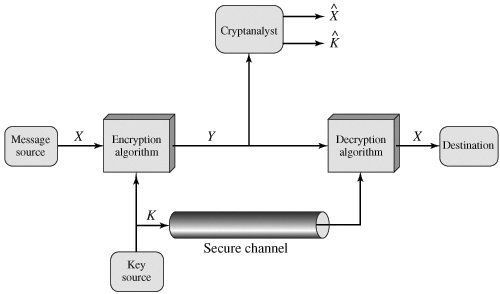
The original Plaintext is converted into apparently random nonsense, called Ciphertext. The Encryption process consists of an algorithm and a key. The key is a value independent of the plain text. The algorithm will produce a different output depending on the specific key being used at the time.Changing the key changes the output of algorithm, the ciphertext.
Once the ciphertext is produced, it may be trasmitted. Upon reception, the ciphertext can be transformed back to the original plaintext by using a descryption algorithm and the same key that was used for encryption.
If we look at picture above, with the message X and the encryption key K as input, the encryption algorithm form the ciphertext.
Y= Ek(X)
The Intended receiver, in possession of the key is able to invert transformation.
X= Dk(Y)
An opponent, observing Y but not having access to K or X, may attempt to recover X or K or both, X and X . It is assumed that the opponent know the encryption (E) and Decryption (D) algorithms. If the opponent is interested in only this particular message, then the focus of the effort is to recover X by generating a plaintext estimate X^. Often, However, the opponent is interest in being able to read future message as well, in which case an attempt is made to recover K by generating and estimate K^.
The Process of attempting to discover X or K or both is known as Cryptanalyst.
-HenSou-
Security Attack, X800 and RFC 2828
Security Attacks
A useful means of classifying security attacks, used both in X.800 and RFC 2828, is in terms of
passive attacks and active attacks. A passive attack attempts to learn or make use of information from the system but does not affect system resources. An active attack attempts to alter system resources or affect their operation.
Passive Attacks
Passive attacks are in the nature of eavesdropping on, or monitoring of, transmissions. The goal of the opponent is to obtain information that is being transmitted. Two types of passive attacks are:
1. release of message contents and
2. traffic analysis.
The release of message contents is easily understood. A telephone conversation, an electronic mail message, and a transferred file may contain sensitive or confidential information. We would like to prevent an opponent from learning the contents of these transmissions.
A second type of passive attack, traffic analysis, is subtler. Suppose that we had a way of masking the contents of messages or other information traffic so that opponents, even if they captured the message, could not extract the information from the message. The common technique for masking contents is encryption.
If we had encryption protection in place, an opponent might still be able to observe the pattern of these messages. The opponent could determine the location and identity of communicating hosts and could observe the frequency and length of messages being exchanged. This information might be useful in guessing the nature of the communication that was taking place(see gnunet).
Passive attacks are very difficult to detect because they do not involve any alteration of the data.Typically, the message traffic is sent and received in an apparently normal fashion and neither the sender nor receiver is aware that a third party has read the messages or observed the traffic pattern. However, it is feasible to prevent the success of these attacks, usually by means of encryption. Thus, the emphasis in dealing with passive attacks is on prevention rather than detection.
Active Attacks
Active attacks involve some modification of the data stream or the creation of a false stream and can be subdivided into four categories:
1. masquerade,
2. replay,
3. modification of messages, and
4. denial of service.
A masquerade takes place when one entity pretends to be a different entity. A masquerade attack usually includes one of the other forms of active attack. For example, authentication sequences can be captured and replayed after a valid authentication sequence has taken place, thus enabling an authorized entity with few privileges to obtain extra privileges by impersonating an entity that has those privileges.
Replay involves the passive capture of a data unit and its subsequent retransmission to produce an unauthorized effect.
Modification of messages simply means that some portion of a legitimate message is altered, or that messages are delayed or reordered, to produce an unauthorized effect. For example, a message meaning "Allow John Smith to read confidential file accounts" is modified to mean "Allow Fred Brown to read confidential file accounts."
The denial of service prevents or inhibits the normal use or management of communications facilities. This attack may have a specific target; for example, an entity may suppress all messages directed to a particular destination (e.g., the security audit service). Another form of service denial is the disruption of an entire network, either by disabling the network or by overloading it with messages so as to degrade performance.
Active attacks present the opposite characteristics of passive attacks. Whereas passive attacks are difficult to detect, measures are available to prevent their success. On the other hand, it is quite difficult to prevent active attacks absolutely, because of the wide variety of potential physical, software, and network vulnerabilities.Instead, the goal is to detect active attacks and to recover from any disruption or delays caused by them. If the detection has a deterrent effect, it may also contribute to prevention.
The Threat and Attack, RFC 2828
Threat
Threat
a potential for violation of security, which exists when is a circumstance,
capability, action, or event that could breach security and cause harm. that is,
a threat is a possible danger that might exploit a vulnerability
Attack
An assault on system security that derives from an intelligent threat; that is,
an intellinget act that is a deliberate attempt (especially in the sense of a
method or technique) to evade security services and violate the security policy
of a system
Is X.800 Important???
The OSI security architecture
To assess effectively the security needs of an organization and to evaluate and choose various security products and policies, the manager responsible for security needs some systematic way of defining the requirements for security and characterizing the approaches to satisfying those requirements. This is difficult enough in a centralized data processing environment; with the use of local and wide area networks, the problems are compounded.
ITU-T Recommendation X.800, Security Architecture for OSI, defines such a systematic approach. The OSI security architecture is useful to managers as a way of organizing the task of providing security. Furthermore, because this architecture was developed as an international standard, computer and communications vendors have developed security features for their products and services that relate to this structured definition of services and mechanisms.
Recap:
Security architecture for OSI(The OSI security architecture was developed in the context of the OSI protocol architecture), define such a systematic approach. The OSI security architecture is useful to managers, as a way of organizing the task of providing security.
It was developed as an international standard.
The OSI security architecture provides a useful, if abstract, overview of many of the concepts that focuses on security attacks, mechanisms, and services. These can be defined briefly as follows:
Security attack: Any action that compromises the security of information owned by an organization.
Security mechanism: A process (or a device incorporating such a process) that is designed to detect, prevent, or recover from a security attack.
Security service: A processing or communication service that enhances the security of the data processing systems and the information transfers of an organization. The services are intended to counter security attacks, and they make use of one or more security mechanisms to provide the service.
ITU X.800 is a security/threat model for end to end communication.
Standard consists of Planes and Layers as well as security dimensions to provide very efficient Architecture and security for end to end communication.
There are eight security dimensions addresses to network vulnerability which are listed below with brief explanation and a way of how can they be implemented:
• Access Control – as it can be understood by its name it controls the access to services such as routers, switches, firewalls etc. Implementation can be done in the configuration of such network element or host and for example linking authentication server with these elements.
• Authentication – request of proving subjects identity by for instance digital certificate.
• Non-repudiation – as far as I understand this section keeps the logs and has abilities to do some actions.
• Data Consistency – Provides for instance encryption based on our organization file classification to make sure that our sensitive data is protected.
• Communication Security – that’s security between point A and B. Uses of non-obscured protocols such as VPN so that sniffing or eavesdropping becomes very unlikely.
• Data integrity – checks that both incoming and outgoing data is correct – means for instance if we request 308kb we should receive the same size file on the destination host.
• Availability – makes sure that legitimate users have got access to all necessary network elements and application according to what they suppose to do (role).
• Privacy – provides again encryption of data as one way of implementation but also for instance Network Address Translation (NAT) to protect internal hosts and redirect all the incoming traffic to the border firewall.
| X.800 defines a security service as a service provided by a protocol
layer of communicating open systems, which ensures adequate security of
the systems or of data transfers. Perhaps a clearer definition is found
in RFC 2828, which provides the following definition: security service is a processing or communication service that is provided by a system to give a specific kind of protection to system resources; security services implement security policies and are implemented by security mechanisms. X.800 divides these services into five categories and fourteen specific services (Table 1.2). We look at each category in turn(There is no universal agreement about many of the terms used in the security literature. For example, the term integrity is sometimes used to refer to all aspects of information security. The term authentication is sometimes used to refer both to verification of identity and to the various functions listed under integrity in this text. Our usage here agrees with both X.800 and RFC 2828) [shadow=red,left]Table 1.2[/shadow]
Authentication The authentication service is concerned with assuring that a communication is authentic. In the case of a single message, such as a warning or alarm signal, the function of the authentication service is to assure the recipient that the message is from the source that it claims to be from. In the case of an ongoing interaction, such as the connection of a terminal to a host, two aspects are involved. 1. First, at the time of connection initiation, the service assures that the two entities are authentic, that is, that each is the entity that it claims to be. 2. Second, the service must assure that the connection is not interfered with in such a way that a third party can masquerade as one of the two legitimate parties for the purposes of unauthorized transmission or reception. Two specific authentication services are defined in X.800: 1. Peer entity authentication: Provides for the corroboration of the identity of a peer entity in an association. It is provided for use at the establishment of, or at times during the data transfer phase of, a connection. It attempts to provide confidence that an entity is not performing either a masquerade or an unauthorized replay of a previous connection. 2. Data origin authentication: Provides for the corroboration of the source of a data unit. It does not provide protection against the duplication or modification of data units. This type of service supports applications like electronic mail where there are no prior interactions between the communicating entities. Access Control In the context of network security, access control is the ability to limit and control the access to host systems and applications via communications links. To achieve this, each entity trying to gain access must first be identified, or authenticated, so that access rights can be tailored to the individual. Data Confidentiality Confidentiality is the protection of transmitted data from passive attacks. With respect to the content of a data transmission, several levels of protection can be identified. The broadest service protects all user data transmitted between two users over a period of time. For example, when a TCP connection is set up between two systems, this broad protection prevents the release of any user data transmitted over the TCP connection. Narrower forms of this service can also be defined, including the protection of a single message or even specific fields within a message. These refinements are less useful than the broad approach and may even be more complex and expensive to implement. The other aspect of confidentiality is the protection of traffic flow from analysis. This requires that an attacker not be able to observe the source and destination, frequency, length, or other characteristics of the traffic on a communications facility(see gnunet). Data Integrity As with confidentiality, integrity can apply to a stream of messages, a single message, or selected fields within a message. Again, the most useful and straightforward approach is total stream protection. A connection-oriented integrity service, one that deals with a stream of messages, assures that messages are received as sent, with no duplication, insertion, modification, reordering, or replays. The destruction of data is also covered under this service. Thus, the connection-oriented integrity service addresses both message stream modification and denial of service. On the other hand, a connectionless integrity service, one that deals with individual messages without regard to any larger context, generally provides protection against message modification only. We can make a distinction between the service with and without recovery. Because the integrity service relates to active attacks, we are concerned with detection rather than prevention. If a violation of integrity is detected, then the service may simply report this violation, and some other portion of software or human intervention is required to recover from the violation. Alternatively, there are mechanisms available to recover from the loss of integrity of data, as we will review subsequently. The incorporation of automated recovery mechanisms is, in general, the more attractive alternative. Nonrepudiation Nonrepudiation prevents either sender or receiver from denying a transmitted message. Thus, when a message is sent, the receiver can prove that the alleged sender in fact sent the message. Similarly, when a message is received, the sender can prove that the alleged receiver in fact received the message. Availability Service Both X.800 and RFC 2828 define availability to be the property of a system or a system resource being accessible and usable upon demand by an authorized system entity, according to performance specifications for the system (i.e., a system is available if it provides services according to the system design whenever users request them). A variety of attacks can result in the loss of or reduction in availability. Some of these attacks are amenable to automated countermeasures, such as authentication and encryption, whereas others require some sort of physical action to prevent or recover from loss of availability of elements of a distributed system. X.800 treats availability as a property to be associated with various security services. However, it makes sense to call out specifically an availability service. An availability service is one that protects a system to ensure its availability. This service addresses the security concerns raised by denial-of-service attacks. It depends on proper management and control of system resources and thus depends on access control service and other security services. |
|
Subscribe to:
Comments (Atom)


